拉去指定docker镜像(目前pytorch支持到pytorch1.3,python3.7)
1 | docker pull python:3.7 |
运行容器
1 | docker run -dit python:3.7 |
比如python自带的字典里,可以存numpy.ndarray类型数据、迭代等,这可能是因为python存的都是对一个数据的引用,所以可以存很多类型。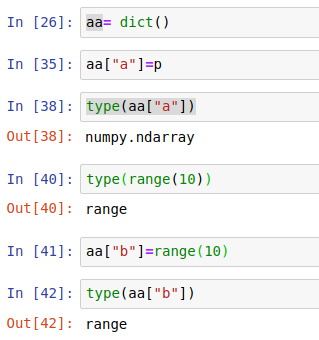
使用的是siege进行的压测: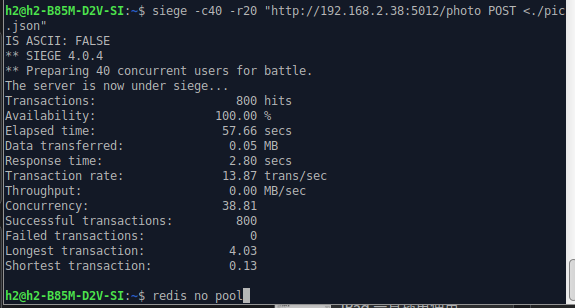
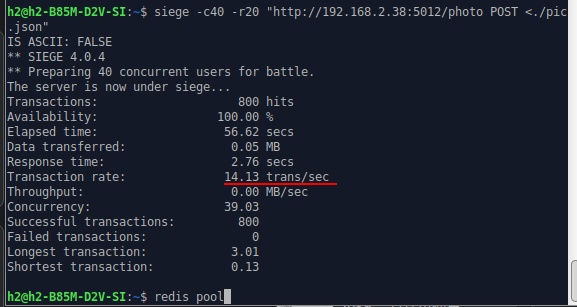
从图上可以看到对于高并发使用线程池后在各项响应时间上都有提升的。
可见在高并发,尤其是和tornado搭配使用的时候务必使用redis且用线程池。
tornado和redis有很多相似的地方比如都是单线程,都是非阻塞IO。
它两个应该配合使用,应该作为在相应方面的主要工具,毕竟速度越快越好。
使用异步非阻塞服务器可以同时响应较多的请求。
同时,可以把写操作先存内存数据库,每小时或其他时长写到硬盘一次。
tornado不用再使用WSGI服务器了,从基础上保证比较快。
如果是使用flask的话,还要使用一个WSGI服务器才能保证速度。
要修改配置bind只能在配置文件中修改
修改指令1
sudo vim /etc/redis/redis.conf
在4%左右的位置将原bind修改为:1
2#bind 127.0.0.1 ::1
bind 0.0.0.0
重启redis1
/etc/init.d/redis-server restart
1 | Most of the work of a Tornado web application is done in subclasses of RequestHandler. |
Tornado Web应用程序的大部分工作都是在RequestHandler的子类中完成的。1
The main entry point for a handler subclass is a method named after the HTTP method being handled:get(), post(), etc.
处理程序子类的主要入口点是以处理HTTP方法命名的方法:get(), post()等。1
Each handler may define one or more of these methods to handle different HTTP actions.
每个处理程序可以定义一个或多个这些方法来处理不同的HTTP操作。1
As described above, these methods will be called with arguments corresponding to the capturing groups of the routing rule that matched.
如上所述,将使用与匹配的路由规则的捕获组相对应的参数来调用这些方法。
第一次把站点地图推送到百度、google是10-14,过了8天了。
google收录的比较快,但是也是略有延后,也不是什么都收录。
百度收录的更慢更少。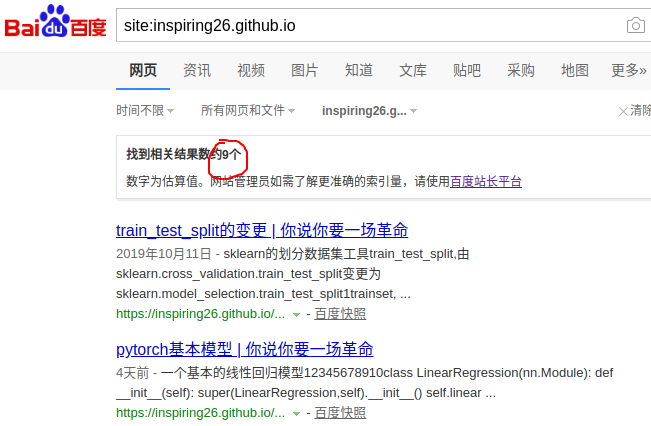
一个比较少用但是要知道的是python自带的函数reversed1
2
3
4
5>>> aa=[1,2,3,4,5]
>>> reversed(aa)
<list_reverseiterator object at 0x7f1e06712978>
>>> list(reversed(aa))
[5, 4, 3, 2, 1]
第二个是修改步长为-11
2>>> aa[::-1]
[5, 4, 3, 2, 1]
python自带的glob模块可以获取指定文件夹的文件,可以使用简单的通配符去匹配。
返回的结果只包含文件名的列表,不包含文件夹。1
2
3
4
5
6>>> import glob
>>> pics = glob.glob("*.jpg")
>>> pics[:2]
['6300509598986346813_n.jpg', '120A2FD38AAC66414265A657BCFDA175.jpg']
>>> len(pics)
15
如此一来,用python处理文件夹内的文件就非常方便了。