获取文件夹内所有文件名
1 | import os |
移动文件等shell操作
1 | import os |
见到这种用法1
sys.path.append(ROOT_DIR)
查看文档后知道
python只有sys.path方法,它是一个列表,里面记录的是python搜索模块的路径。
原话是A list of strings that specifies the search path for modules.
一个字符串列表,列表指定了模块的搜索路径。
再具体一点,其初始化的时候是从PYTHONPATH中获取的地址字符串。
可以通过以下shell命令来获取网站的状态码1
curl -o /dev/null -s -w "%{http_code}" "http://192.168.1.111:5006/login/"
返回结果是200
以我的网站为例,打开连接https://ziyuan.baidu.com/crawltools/index?site=http://inspiring26.github.io/
在空格处补全输入其中一篇文章的地址:
1
2019/11/05/使用python建立两台电脑之间的连接
抓取后的结果:
点击抓取失败,查看详情: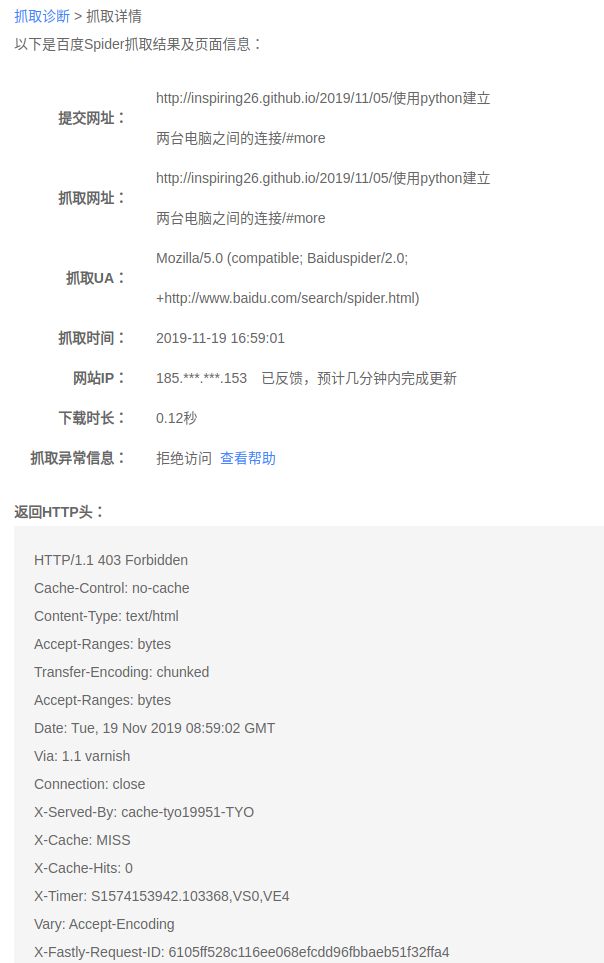
df = …
loc和iloc是直接读取行的
区别在iloc参数是数字,loc参数是字符串
读取列的话,有三种,分别是. [] 上面两种的应用
df.0
df[0]
df.loc[:,[]] df.iloc[:,[]] #内部的方括号中不能用切片,可以列举。外部的可以用切片
两步。
1,让homepod播放指定音乐列表或指定风格音乐
2,让homepod在指定时间后停止播放
让homepod在指定时间开始播放音乐,用作起床闹钟。1
You’re permitted to ask Siri to set up a sleep timer for anywhere from a couple of seconds to 23 hours and 59 minutes. What you cannot do is ask the assistant to set a sleep timer for a precise time, like 11pm. And lastly, you obviously cannot make multiple sleep timers.
是不能精确定时的,那就测测若干时间后停止播放。
不管是bert类的大规模预训练模型,还是视觉领域最新的把ImageNet准确率提升1%的Noisy Student,他们一个共同的特点,非监督学习。非监督学习的好处是数据大,通过大规模数据更容易学到其中的隐含规律、一般规律。
bert用了一种很巧妙的方法,开了个好头,一个新的思维方向。
数据量很多没法标注对把,我们可以把模型的结果设置称一种简单的关系,我们的目标是通过大量隐藏层去学到一个语言的内在关系。
bert采用的方法:
1,是使用两句话是否为上下句这种关系作为标签。这种关系不需要人工标注,通过简单的算法记录一下哪些是被分割开的就能实现。
2,还有一种方法是遮蔽部分词,让模型去预测,这种方法同样不需要标注数据,因为标签就是你遮蔽掉的词。
3,不仅仅做一种预测训练,既做了只有两个类别的上下句预测,又做了预测单词的非分类。我感觉这样使模型输出的结果不同,尽量减少对单一特定任务的效果,而是通过切换最后一层功能,尽量使模型学到的只是语言的特点,具体来说会在较深的层次中对各种词语搭配、句子骨干比较敏感,做出相应的反馈。
举个例子:
词语块:1
2
3解放碑吃火锅
农民辛苦 水稻
...
骨干类:1
2
3xxx 是 xxx 榜样
xxx 省 xxx 市
...