什么是编码
计算机是01二进制的,我们看到的文字等数据和二进制的转换规则就是编码。
编码历史
漂亮国发明计算机后,用8位01组合(2^8=256)做出了第一个转换规则,就是所谓的ASCII表。
计算机进入中国256个字符不够用,还要表示汉字呢,于是对ASCII进行了扩展,就是GB2312。
后续又不够用,扩展为GB18030。
同理每个国家都有自己的编码。必须安装这种编码才能看懂对应意思。
后来国际上起草了一个统一编码能表示任何国家的文字,就是UNICODE。使用的是两个字节2^16=65536表示所有文字,好像并不多啊。
然后漂亮国觉得自己吃亏了,本来一个字节就可以表示的,浪费一倍存储空间。
于是提出了一种新的格式,较通用转换格式UTF,这个U就是UNICODE,常见的有utf-8,utf-16,说白了就是一种变长编码方法,信息论里常见的很,于是美国一个字节,欧洲两个字节,东南亚三个字节,感觉我们吃亏了一个字节。
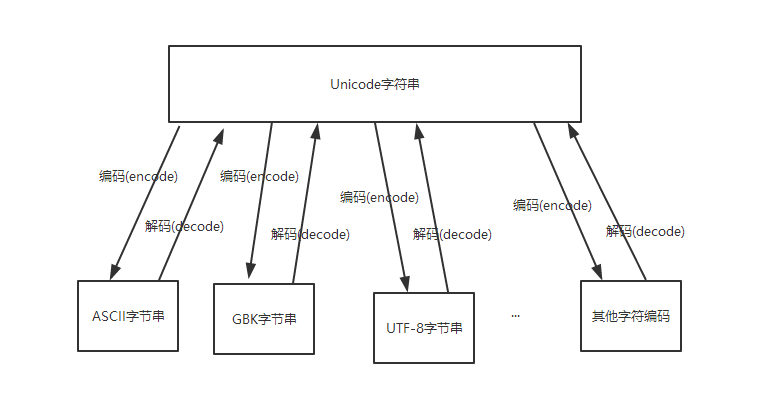
decode和encode
python内部是unicode,以unicode作为中间编码,其他编码需要先解码成unicode,再从unicode编码成另一种编码。
python里的字符串是unicode编码的,可以看作是python在内存中的原始编码,转化为其他的如GB2312、utf-8需要编码,是编码,即python的unicode到其他编码方式间都是编码,编码。反过来才是解码。
以下编码都是可以的:1
2
3
4
5
6
7
8
9
10
11
12>>> aa="abc";type(aa)
<class 'str'>
>>> bb=aa.encode("utf-8");type(bb)
<class 'bytes'>
>>> cc=aa.encode("utf-16");type(cc)
<class 'bytes'>
>>> dd=aa.encode("GB2312");type(dd)
<class 'bytes'>
>>> ee=aa.encode("GB18030");type(ee)
<class 'bytes'>
>>> ff=ee.decode("GB18030");type(ff)
<class 'str'>
从上面代码可以看到不是unicode就是不str,只要是unicode编码的就是str,其他编码都是bytes
unicode可以看作底层的统一的,它到其他都是编码。
关系图